Manual de desarrollo de backend
Historial de versiones
| Versión | Fecha | Descripción |
|---|---|---|
| 1.0 | 2024-02-15 | Versión inicial |
| 1.1 | 2024-02-18 | Mejora y corrección de errores |
| 1.2 | 2024-03-28 | Migración del documento a Markdown, actualización del contenido y adición del apartado "Estilo de código" |
1. Introducción
Este manual está dirigido al equipo de desarrollo backend y aborda aspectos importantes relacionados con la metodología de trabajo, la gestión y configuración del repositorio, así como otras áreas vitales como las herramientas y licencias utilizadas en el proyecto. Proporciona una guía completa y detallada para que el equipo tenga conocimiento previo de todos los aspectos esenciales de la gestión, configuración y trabajo colaborativo, permitiendo que comiencen el desarrollo del proyecto con una comprensión completa de la metodología y otros aspectos fundamentales.
2. Metodología de trabajo
Se seguirá una metodología de trabajo siguiendo un esquema organizado y colaborativo entre todos los miembros del equipo de desarrollo de backend, con el objetivo de que la comunicación sea fluida entre todos los miembros del equipo y las tareas a realizar estén lo más organizadas posible.
Primeramente, con el objetivo de promover una buena comunicación, el equipo tendrá una reunión semanal cada lunes dónde se tratarán aspectos importantes como la asignación y el seguimiento de tareas, asignación de revisores y demás aspectos que se consideren oportunos.
El equipo recibirá una serie de tareas cada semana, provenientes del product backlog. Dichas tareas serán asignadas a cada miembro en la reunión semanal anteriormente mencionada. Para realizar un seguimiento de las tareas, usaremos un tablero de GitHub Projects. Cabe mencionar que se ha acordado que el contenido del repositorio se realizará en inglés.
Cada tarea se realizará en tres periodos diferentes. En primer lugar se establecerá un plazo para implementar la funcionalidad correspondiente. Luego, se establecerá un segundo plazo para que otro miembro del equipo pueda realizar las pruebas relacionadas con dicha funcionalidad, siempre que sea necesario hacer pruebas. Por último, un miembro distinto a los dos anteriores se encargará de revisar la tarea.
3. Gestión de incidencias
Una incidencia es un problema que se ha detectado, relacionado con el software o la documentación del proyecto. En nuestro caso, una incidencia también suponen tareas de implementación de nueva funcionalidad y mejoras en el repositorio. Se seguirá el siguiente protocolo para la gestión y resolución de incidencias:
-
Se crea una issue en el registro de incidencias que describa cuál es el problema o la funcionalidad y el módulo que afecta. En nuestro caso, el registro de incidencias será un tablero de GitHub Projects, en el que se registran todas las incidencias detectadas.
-
Tras hacerlo, se debe asignar a la persona responsable de realizar los cambios necesarios para corregir el error o implementar la funcionalidad correspondiente, además de etiquetar la gravedad del problema y de especificar de qué tipo de incidencia se trata.
-
Una vez hecho eso, el encargado debe crear una rama para trabajar en la corrección y/o implementación del problema/mejora. Cuando se complete, si la tarea requiere ser testeada, se mencionará en los comentarios de la incidencia al compañero responsable de hacer el test. Cuando se haga el test, el tester debe crear una Pull Request hacia la rama develop para incorporar el cambio y/o corregir el error correspondiente. Para ello, como se mencionó anteriormente, habría que pasar por la revisión otro compañero.
-
Una vez que todo el código ya se encuentra integrado y revisado, dentro de los plazos que se hayan acordado, se moverá la tarea a Done y se cerrará la issue correspondiente, quedando de esta forma la incidencia resuelta.
4. Política de commits
Es importante establecer una política de commits para el proyecto, ya que mensajes de commit claros y descriptivos ayudarán a los miembros del equipo a comprender los cambios realizados en el commit y a rastrear el progreso del proyecto. Se ha elaborado una plantilla de commits que incluye la estructura de commits que usaremos. Los mensajes de commit se harán en inglés. La plantilla es la siguiente:
tipo: asunto #id_issue
cuerpo
### tipo:
# feat (nueva funcionalidad)
# fix (corrección de errores)
# docs (documentación)
# refactor (refactorización)
# research (incorporación de código experimental)
# test (incorporación o modificación de tests)
# conf: (configuración)
### asunto:
# Dreve descripción del cambio. Debe comenzar con mayúscula y con un verbo en participio pasado.
### id_issue:
# Número de la issue relacionada con el commit. Si no hay ninguna, no es necesario incluirlo.
### cuerpo:
# Descripción más detallada del cambio realizado. Es opcional, y solo se incluirá en caso de que el asunto no sea suficientemente descriptivo.
### Ejemplo:
# feat: Added user model #1
5. Estrategia de ramificación
En cuanto a la estrategia de ramificación, se ha decidido usar Git Flow con algunas modificaciones para adaptarlo a la comodiad del equipo. La estraegia se detalla a continuación:
-
Ramas principales: las ramas principales del proyecto serán main y develop, donde se reunirán la funcionalidad estable y la funcionalidad en desarrollo, respectivamente. Ambas ramas están protegidas para permitir las fusiones de código únicamente tras ser aprobadas.
-
Ramas feature: se utilizarán para desarrollar cada una de las tareas asignadas a cada miembro. Estas ramas se crearán a partir de develop. Deberán seguir la siguiente nomenclatura:
feature/id_issue-titulo-descriptivo. -
Ramas hotfix: se utilizarán para corregir errores en producción. Estas ramas se crearán a partir de main y se fusionarán en main y develop una vez finalizadas. Deberán seguir la siguiente nomenclatura: hotfix/
id_issue-titulo-descriptivo. -
Ramas fix: se utilizarán para corregir errores o realizar mejoras en desarrollo. Estas ramas se crearán a partir de la rama sobre la que se quiera realizar la corrección o mejora y se fusionarán en la misma una vez finalizadas. Deberán seguir la siguiente nomenclatura:
fix/id_issue-titulo-descriptivo. -
Ramas doc: se utilizarán para realizar cambios en la documentación. Estas ramas se crearán a partir de develop y se fusionarán en develop una vez finalizadas. Deberán seguir la siguiente nomenclatura:
doc/id_issue-titulo-descriptivo. -
Ramas conf: se utilizarán para realizar cambios en archivos de configuración. Estas ramas se crearán a partir de develop y se fusionarán en develop una vez finalizadas. Deberán seguir la siguiente nomenclatura:
conf/id_issue-titulo-descriptivo.
6. Gestión de versiones
Como sistema de gestión de versiones, usaremos las releases de GitHub. Se ha planificado que se realizará una release cada semana con el objetivo de tener una actualización regular y coherente del proyecto. Además, cada semana se desplegará dicha release en Google Cloud para tener el servicio actualizado.
Como política de versionado, utilizaremos un versionado semántico con la siguiente estructura: [Mayor].[Menor].[Parche]. En los siguientes casos se incrementará el número de versión:
-
Mayor: cambios importantes en el proyecto. Por ejemplo: un cambio que rompe la compatibilidad.
-
Menor: cambios en la funcionalidad del proyecto, ya sean mejoras o nuevas funcionalidades compatibles con versiones anteriores.
-
Parche: correcciones de errores de versiones anteriores. Se pueden agregar etiquetas para versiones preliminares y para la compilación de metadatos, aunque puede significar que la versión no es estable o que no cumple con los requisitos de compatibilidad.
Además, debe cumplir con los siguientes requisitos:
-
Cuando se incrementa el Mayor, Menor y Parche se deben restablecer a 0.
-
Cuando se incrementa el Menor, Parche se debe restablecer a 0.
-
La precedencia se determina por la diferencia al comparar identificadores de izquierda a derecha. Por ejemplo: 1.0.0 < 2.0.0 < 2.1.0.
En nuestro caso, las etiquetas se utilizarán principalmente en versiones de producción. Por ejemplo: la primera versión será 1.0.0.
7. Pruebas y testing
En cuanto a la implementación de pruebas, se ha acordado que cada funcionalidad implementada tendrá que tener una serie de pruebas con el objetivo de garantizar la calidad y buen funcionamiento del código implementado.
Principalmente utilizaremos pruebas unitarias para testear nuestro código, aunque también se ha acordado realizar pruebas de seguridad en los endpoints de nuestra aplicación web. Se hará uso de la metodología de testing “happy path” que se centra en probar principalmente el flujo de trabajo normal de una aplicación, lo que ayuda a garantizar que la funcionalidad básica del sistema esté correctamente implementada y funcione como se espera. Además, se tendrán en cuenta los principales casos de errores de cada funcionalidad. Se ha establecido que al menos se probará un caso de error por cada funcionalidad implementada.
Para aplicar correctamente esta estrategia de testing, es necesario identificar y probar los flujos de trabajo principales de la aplicación y se deberán desarrollar casos de prueba que cubran estos flujos. Seguidamente, hay que ejecutar las pruebas y documentar los resultados. Si hubiera algún problema, habría que repetir el proceso tantas veces como sea necesario para corregirlos. Con esta estrategia, es necesario que las pruebas alcancen entre un 70 y un 80 % de cobertura de código para que se consideren lo suficientemente válidas.
Por último, para la implementación de pruebas se seguirá la siguiente metodología de trabajo dentro del equipo de desarrollo de backend: cada miembro implementará su tarea correspondiente y luego otro miembro diferente del equipo implementará las pruebas de dicha funcionalidad. Esta forma de trabajo tiene como principal ventaja la detección de posibles errores que no se hayan tenido en cuenta por parte de la persona que haya implementado la funcionalidad, lo que aumentaría la calidad del software. Además, promueve una mejor colaboración entre los miembros del equipo y un mayor conocimiento de toda la funcionalidad implementada.
Proceso de testing
El proceso de asignación de cada test se realizará en la reunión semanal del backend, cuando la feature en desarrollo se termine el miembro responsable de esta feature avisará al encargado de realizar el test y añadirá un comentario en la issue de la feature en la plataforma GitHub especificando y mencionando a la persona responsable del test que ya se puede realizar el test de la funcionalidad. Cuando el test se haya realizado, el encargado de realizar el test creará una Pull Request en GitHub y asignará al revisor correspondiente, avisando en el canal de Discord especificado para realizar este tipo de avisos.
Estrucutra de los tests
La estructura de los tests queda definida de la siguiente manera:
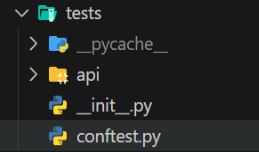
En esta estructura el archivo conftest.py, es donde están definidas todas las funcionalidades globales del testing, como la funcionalidad para crear una instancia de FastAPI para ejecutar tests. En el directorio api se establecen los tests de integración del proyecto.
El formato para los ficheros test del directorio api es el siguiente: test_<nombre organización>_<recurso testeado>.py. Ej: para el archivo de testing del recurso de family que tiene la organización cyc, el nombre será el siguiente test_cyc_family.py.
El nombre de la función test que se va a ejecutar sigue el siguiente formato: test_<nombre de la funcion router testeada>. Ej: para un POST cuya función en router se llama create_family, la función de test se nombrará como test_create_family..
8. Protección de ramas
Las ramas protegidas serán las dos ramas principales del repositorio: main y develop. Estas ramas quedarán protegidas y deberán de cumplirse una serie de condiciones para poder integrar código en esas ramas, con el objetivo de evitar errores o código de baja calidad en producción. Las condiciones de protección que deben cumplirse son las siguientes:
-
La pull request debe ser revisada y aprobada por al menos un revisor para la rama develop y dos revisores para la rama main. Hasta que no se cumpla esta condición, no se podrá integrar el código en la rama correspondiente.
-
Los workflows de GitHub Actions deben ejecutarse correctamente para poder integrar el código. Esto supone que las pruebas deben ejecutarse correctamente sin errores, el código debe tener un mínimo de calidad y debe seguir el formato adecuado definido en el workflow.
-
Además, se definirá una restricción que establezca que la rama que se intente fusionar debe estar actualizada, es decir, que debe tener los mismos commits que la rama a la que se está intentado fusionar. Esto se hace con el objetivo de reducir considerablemente los conflictos que puedan surgir en el momento de realizar la fusión entre ambas ramas.
9. Gestión de pull requests
Para la gestión y revisión de pull requests se ha definido una plantilla Markdown de solicitud de cambio. Es imprescindible el uso de la plantilla para garantizar la correcta revisión de las funcionalidades implementadas. Su estructura es la siguiente:
## Description
[Explain the purpose of this pull request and the changes it introduces]
## Related Issue(s)
- [Mention the related issue(s) if they exist]
## Checklist
- [ ] I have read and followed the project's contributing guidelines.
- [ ] I have tested the changes locally.
- [ ] I have made corresponding changes to the documentation if necessary.
- [ ] My code follows the project's code style guidelines.
## Reviewer
- @reviewer
## Tester (if applicable)
- @tester
## Screenshots (if applicable)
[Add screenshots or GIFs to visually demonstrate the changes, if applicable]
## Notes (if applicable)
[Add any additional notes or context for reviewers, if applicable]
10. Gestión de dependencias
Para la gestión de dependencias del proyecto, hemos optado por adoptar Pipenv en lugar del tradicional requirements.txt. Pipenv es una herramienta avanzada que ofrece una serie de beneficios significativos para el manejo eficiente de las dependencias y entornos virtuales en proyectos de Python. A continuación, se detallan las razones clave de esta elección y cómo Pipenv mejora nuestro flujo de trabajo de desarrollo:
Resolver y Actualizar Dependencias Automáticamente
-
Resolución de Dependencias: Pipenv utiliza un algoritmo sofisticado para resolver las dependencias de los paquetes, lo que ayuda a evitar conflictos y asegura que se instalen versiones compatibles de cada paquete.
-
Actualizaciones Seguras: Con el comando pipenv update, Pipenv permite actualizar las dependencias de manera segura, respetando las versiones especificadas en el Pipfile.lock, lo que garantiza la estabilidad del entorno de desarrollo y producción.
Gestión de Entornos Virtuales
-
Entornos Aislados: Pipenv crea automáticamente un entorno virtual para cada proyecto, lo que significa que las dependencias de un proyecto no afectarán a otros proyectos en el mismo sistema.
-
Activación y Ejecución: Los entornos virtuales se pueden activar con pipenv shell o se pueden ejecutar comandos directamente en el entorno con pipenv run, simplificando el flujo de trabajo.
Consistencia entre Entornos
- Pipfile y Pipfile.lock: Pipenv introduce el Pipfile para declarar dependencias de forma abstracta y el Pipfile.lock para fijar las versiones exactas, lo que asegura que todos los desarrolladores y los entornos de despliegue utilicen las mismas versiones de las dependencias.
Compatibilidad y Seguridad
-
Compatibilidad con requirements.txt: Pipenv es compatible con requirements.txt, lo que permite una transición suave de proyectos que utilizan el formato tradicional.
-
Verificación de Seguridad: Con pipenv check, se pueden identificar vulnerabilidades de seguridad en las dependencias instaladas, mejorando la postura de seguridad del proyecto.
Facilidad de Uso y Mantenimiento
- Interfaz de Usuario Intuitiva: Pipenv ofrece una interfaz de línea de comandos coherente y fácil de usar, lo que facilita la gestión de dependencias para desarrolladores de todos los niveles.
- Documentación Clara: La documentación de Pipenv es completa y fácil de seguir, lo que ayuda a los nuevos desarrolladores a ponerse al día rápidamente.
11. Estilo de código
Gestión de imports
El proceso de importación de servicios y modelos se ha estandarizado como sigue:
-
Para los servicios, se utiliza la estructura
from src.modules.shared.user import servicesi se está dentro del módulo de usuario. Si se está utilizando el servicio de usuario desde otro módulo, se emplea la siguiente sintaxis:from src.modules.shared.user import service as user_service. -
Para los modelos, se emplea la misma estructura que para los servicios, pero con la palabra
modelen lugar deservice. -
Los imports se organizan en el siguiente orden,
- Librerías externas, incluyendo Pydantic.
- Imports del framework.
- Imports internos.
-
Cada categoría de importaciones se separa por una línea en blanco. Un ejemplo de esta organización sería:
from pydantic import ValidationError
from jose import jwt, JWTError
from fastapi import HTTPException, status
from fastapi.security import OAuth2PasswordRequestForm
from src.core.config import settings
from src.core.deps import DataBaseDep
from src.modules.shared.auth import service
from src.modules.shared.auth import model
from src.modules.shared.user import service as user_service
Documentación de funciones
Cada router incluye un docstring que documenta su funcionalidad (que también se exporta al Swagger) y especifica los tipos de errores que pueden surgir en el controlador, junto con una descripción. Aquí se puede ver un ejemplo:
@router.post(
'/login',
status_code=status.HTTP_200_OK,
response_model=model.TokenSchema,
responses={
200: {"description": "Token successfully generated"},
401: {"description": "Incorrect email or password"},
}
)
async def login(
db: DataBaseDep,
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
"""
Authenticates a user and generates an access and refresh token.
Errors:
- 401: Incorrect email or password
"""
return await controller.login_controller(db, form_data)
Cada función del router ahora sigue este estándar para mejorar la documentación y la comprensión del manejo de errores en el código.
Nomenclatura de endpoints
Ninguno debe terminar en "/". Ejemplos:
GET /api/v1/cyc/deliveryPOST /api/v1/cyc/delivery
12. Entorno de desarrollo
El equipo de trabajo ha acordado por unanimidad trabajar con Visual Studio Code debido a su gran polivalencia y su facilidad de entendimiento y personalización.
Cabe mencionar que cada desarrollador adaptará su entorno mediante plugins y configuraciones personales para un mejor desempeño de su actividad.
Es necesario seguir el manual de instalación del gestor de dependencias incluido en el Anexo II del presente documento.
13. Herramientas de desarrollo
Algunos de los integrantes del equipo usarán WSL (Windows Subsystem for Linux), que permitirá a los desarrolladores evitar el uso de máquinas virtuales externas y facilitará el acceso a herramientas de un sistema Linux desde su entorno Windows. Su uso va ligado al uso de Docker para la gestión de contenedores. Se necesita Windows 10+.
Otras herramientas fundamentales en el desarrollo del proyecto las Inteligencias Artificiales, principalmente GitHub Copilot, ChatGPT y Perplexity.ai. Todas ellas se han estado utilizando durante todas las fases del proyecto mejorando la calidad de la solución software final. Cabe recordar que su uso será registrado en la documentación oficial de la empresa.
14. Herramientas de análisis de código
Siguiendo la senda de las metodologías ágiles y DevOps hemos decidido establecer un sistema autónomo de análisis de código de la mano de Codacy.
Para ello se implementará un sistema de flujo de código automatizado con GitHub Actions que permitirá tener un informe completo del código generado durante la implementación de una funcionalidad, accesible durante la revisión de la solicitud de cambio (PR).
La utilización de esta herramienta será fundamental en la obtención de métricas y estadísticas que nos informen del nivel de calidad del código implementado incrementando el valor final del producto.
15. Licencia de software
El proyecto Harmony utiliza la Licencia Pública General Affero de GNU, versión 3 (AGPL v3) como su licencia de software libre. Publicada por la Free Software Foundation, esta licencia se diferencia de la GNU GPL v3 principalmente en que cierra la "brecha de servicio en la nube". Esto significa que si el software se modifica y se utiliza para ofrecer servicios a través de una red, como Internet, el código fuente de las versiones modificadas debe estar disponible para los usuarios de esos servicios bajo los términos de la AGPL v3. Algunos aspectos destacados de la AGPL v3 incluyen:
-
Libertades del Usuario: Al igual que la GPL v3, la AGPL v3 garantiza a los usuarios las libertades fundamentales para usar, estudiar, compartir (copiar) y modificar el software.
-
Compatibilidad con Patentes: La AGPL v3 también aborda el tema de las patentes de software, asegurando que los usuarios tengan permiso para utilizar cualquier patente que cubra el software distribuido bajo esta licencia.
-
Protección contra DRM: Prohíbe la imposición de medidas técnicas efectivas que restrinjan a los usuarios a modificar o ejecutar el software modificado.
-
Compatibilidad con Versiones Anteriores: Permite que el software distribuido bajo versiones anteriores de la GPL pueda ser actualizado a la AGPL v3.
-
Responsabilidad Limitada: Establece que los autores y distribuidores del software no ofrecen garantías y no asumen responsabilidad por ningún daño resultante del uso del software.
La adopción de la AGPL v3 por parte de Harmony refleja nuestro compromiso con la libertad del software y la transparencia, especialmente en el contexto de aplicaciones web y servicios en la nube, asegurando que nuestra comunidad pueda beneficiarse de las mejoras incluso cuando el software se ejecuta como un servicio. Este cambio refleja un compromiso más fuerte con la transparencia y la libertad del software, especialmente importante en el contexto de los servicios en la nube, donde los usuarios finales podrían interactuar con versiones modificadas del software sin tener acceso directo al código fuente. La AGPL v3 asegura que incluso en estos casos, los usuarios tengan acceso al código fuente modificado, fomentando así un ecosistema de software más abierto y colaborativo.
16. CI/CD pipeline
En esta sección, se recogen, de manera breve, los procedimientos que se implementarán para agilizar el proceso de desarrollo del equipo de backend. Los aspectos principales son los siguientes:
-
Automatización de pruebas: como parte del proceso de integración continua, tenemos configurado el lanzamiento automatizado del conjunto de tests que prueben cada una de las funcionalidades que integran un incremento en el producto. La ejecución de estos tests junto a las revisiones, garantizan el correcto funcionamiento de la base de código, identificando errores antes de la integración. En este sentido, optimizan el proceso de revisión, al automatizar la evaluación de aspectos básicos, permitiendo a los revisores centrarse en detalles más abstractos y complejos.
-
Evaluación de la calidad y el formato del código: Paralelamente, ejecutamos rutinas para evaluar la calidad del código y su conformidad con la guía de estilo PEP8. Utilizamos procedimientos automatizados que no solo analizan el código, sino que también pueden generar PR de refactorización para que el código se alinea con las mejores prácticas de estilo. Con este enfoque buscamos garantizar la coherencia y la legibilidad del código, facilitando el mantenimiento y la colaboración.
-
Intercepción de fallos en las etapas 1. y 2.: Si algún test falla, o la calidad del código y su formato no cumplen lo estipulado en este documento, la PR no podrá ser fusionada con las ramas principales, develop y main.
-
Despliegue del incremento semanal: En caso de superar las condiciones anteriores, si la PR se crea desde la rama de desarrollo (development) a la rama de producción (main), versionando el incremento de manera adecuada:
-
Versionado del sistema: Registrar una imagen de Docker con la versión del sistema a fecha de cierre del sprint, encapsulando todas las dependencias necesarias para lanzarlo (no incluye servicios externos como la base de datos). Esta configuración nos permite comprobar la funcionalidad de los diferentes incrementos en el entorno de producción.
-
Despliegue del sistema: Subir la imagen de la etapa anterior al registro de artefactos de Google Cloud. Este proceso garantiza una entrega continua y eficiente, minimizando el tiempo de inactividad y maximizando la disponibilidad del sistema. Este enfoque de despliegue, asegura que las nuevas funcionalidades y correcciones estén rápidamente al alcance del usuario de la aplicación.
-
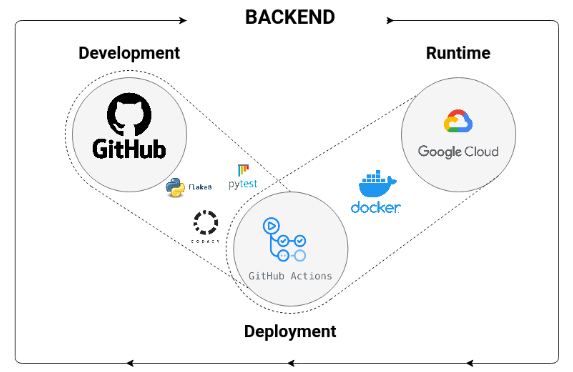
A continuación se muestra un diagrama con nuestro procedimiento de desarrollo actual, ejemplificando lo anterior:
Anexo I: Material para la presentación
Metodología de trabajo
-
Se seguirá una metodología organizada y colaborativa entre los miembros del equipo de desarrollo de backend.
-
Reunión semanal para asignación y seguimiento de tareas, además de otros aspectos relevantes.
-
Uso de un tablero de GitHub Projects para el seguimiento de tareas.
-
Plazos para implementación y pruebas de funcionalidades.
-
El contenido del repositorio se realizará en inglés.
Gestión de incidencias
Protocolo para la gestión y resolución de incidencias, creando issues en el registro de incidencias, asignando responsables, etiquetando la gravedad del problema y el señalando el tipo de incidencia, creando ramas y pull requests, y cerrando la issue una vez resuelta.
Política de commits
Uso de una plantilla de commits con mensajes en inglés.
Estrategia de ramificación
Uso de Git Flow adaptado, con ramas principales (main y develop), ramas feature, hotfix, fix, doc y conf.
Gestión de versiones
Uso de releases de GitHub con un versionado semántico.
Pruebas y testing
-
Implementación de pruebas unitarias y pruebas de seguridad en los endpoints.
-
Uso de la metodología "happy path" para probar el flujo normal de la aplicación.
-
Metodología de trabajo para la implementación de pruebas, con un miembro implementando la funcionalidad y otro las pruebas.
Protección de ramas
Condiciones para integrar código en las ramas principales (main y develop).
Gestión de pull requests
Plantilla para la gestión y revisión de pull requests.
Gestión de dependencias
Uso de Pipenv en lugar del tradicional requirements.txt para la gestión eficiente de dependencias en proyectos de Python.
Entorno de desarrollo
Uso acordado de Visual Studio Code con personalización mediante plugins y configuraciones personales.
Herramientas de desarrollo
-
Uso acordado de WSL (Windows Subsystem for Linux) y Docker.
-
Utilización de IAs como Copilot, ChatGPT y Perplexity.ai.
Herramientas de análisis de código
Establecimiento de un sistema autónomo para el análisis continuo del código.
Anexo II: Instalación de Pipenv en Windows
-
Verificar la Instalación de Python y Pip Antes de instalar Pipenv: asegúrate de que Python y pip (el gestor de paquetes de Python) estén instalados en tu sistema. Abre la línea de comandos (cmd) y verifica la versión de Python:
python --versionDeberías ver la versión de Python si está instalado correctamente. Verifica la versión de pip:
pip --versionSi pip está instalado, verás la versión y la ubicación de Python a la que está asociado.
-
Pipenv se puede instalar utilizando pip. Es recomendable instalar Pipenv solo para tu usuario para evitar conflictos con otros proyectos o configuraciones del sistema. En la línea de comandos, ejecuta el siguiente comando para instalar Pipenv:
pip install --user pipenvDespués de la instalación, agrega la ruta al directorio de scripts de Python a tu variable de entorno PATH para poder ejecutar Pipenv desde cualquier lugar. Puedes encontrar esta ruta ejecutando el siguiente comando en la línea de comandos:
python -c "import site; import os; print(os.path.join(site.USER_BASE, 'bin'))"Copia la ruta resultante y agrégala a la variable de entorno PATH a través del Panel de Control de Windows o la línea de comandos.
-
Verificar la Instalación de Pipenv: Para asegurarte de que Pipenv se ha instalado correctamente y está disponible en la línea de comandos, ejecuta:
pipenv --versionDeberías ver la versión de Pipenv instalada.
-
Crear un Entorno Virtual y Gestionar Dependencias: Navega a la carpeta de tu proyecto en la línea de comandos:
cd path\to\your\projectPara crear un entorno virtual y un Pipfile para tu proyecto, ejecuta:
pipenv installEsto creará un entorno virtual específico para tu proyecto y un Pipfile que se utilizará para gestionar las dependencias. Para activar el entorno virtual, utiliza:
pipenv shellEsto activará el entorno virtual y podrás comenzar a trabajar en tu proyecto. Para instalar paquetes y agregarlos a tu Pipfile, usa:
pipenv install <package_name>Para desactivar el entorno virtual y volver al entorno global, simplemente escribe exit en la línea de comandos.
-
Manejo de Dependencias: Para instalar todas las dependencias especificadas en el Pipfile, ejecuta:
pipenv installPara desinstalar un paquete y eliminarlo del Pipfile, usa:
pipenv uninstall <package_name>Para generar un Pipfile.lock que asegure la consistencia de las dependencias, ejecuta:
pipenv lock -
Actualizar Pipenv: Para actualizar Pipenv a la última versión disponible, ejecuta:
pip install --user --upgrade pipenv
Anexo III: Instalación WSL
-
Habilitar la Característica de Windows Subsystem for Linux:
- Abre el "Panel de Control" de Windows.
- Haz clic en "Programas" y luego en "Activar o desactivar las características de Windows".
- Busca "Subsistema de Windows para Linux" en la lista, actívalo y haz clic en "Aceptar".
-
Descargar e Instalar una Distribución de Linux desde Microsoft Store:
- Abre Microsoft Store desde el menú de inicio.
- Busca la distribución de Linux que desees (por ejemplo, Ubuntu, Debian, Kali Linux) y descárgala.
- Una vez descargada, haz clic en "Iniciar" desde la página de la distribución en Microsoft Store.
-
Configurar tu Distribución de Linux:
- Cuando se inicie la distribución descargada, se te pedirá que configures un nombre de usuario y contraseña para tu cuenta de usuario de Linux.
-
Utilizar WSL:
- Una vez configurada, podrás acceder a tu distribución de Linux desde el menú de inicio o ejecutando el comando wsl desde la línea de comandos de Windows.
Anexo IV: REST API
Las API que usan la arquitectura REST están orientadas a recursos, donde los métodos HTTP ya van a ser los que den la información sobre qué acción va a realizarse en el servidor.
En nuestro caso, siempre que una acción se realice sobre un recurso, la url tendrá que acabar en el recurso al que se esté accediendo. Ej: si se va a realizar un listado de todas las familias que hay en la db, se realizara un get sobre /api/v1/cyc/family, si se quiere acceder a una familia específica se puede hacer usando el id como parámetro del endpoint /api/v1/cyc/family/{id}.
Para mas información de las buenas prácticas con REST API, se recomienda visitar los siguientes enlaces: